Kubernetes 多集群搞了那么多年了,貌似也没倒腾出比较 stable 的项目,看看现在 kubefed 怎么样。本篇是 kubefed 的开篇。
FBI WARNING: 不喜欢看代码分析的就直接去最后一篇看结论就好
前言
当需要考虑到 Kubernetes 多集群的时候,我们往往是什么样的场景?
- 集群容灾:当某个集群异常的时候迁移到另一个集群中
- 多云容灾:当前在业界的另一个解释是不让云厂控制「你」
- 边缘计算:边缘计算中常常会有多地自治域的存在,所以常常是边缘上有一坨的 Kubernetes 集群(没用 Kubernetes 当我没说)
- 普普通通的多集群:真就很普通的多集群,服务需要部署多集群(虽然也是容灾,但不是为了 Kubernetes 的容灾而是服务的容灾)
k8s 在这个 SIG 的路确实走的有点久,从最开始的 Kubernetes Federation 再到推倒重写 kubefed,虽然浩浩荡荡但是还没有 GA。有些厂提供了 kubefed 的能力个用户,也有些许大厂自己做多集群,比如 Anthos、Rancher 等等。 所以究竟 kubefed 是怎么样的一个东西,值得去用吗?不知道,但里面一定有值得学的。
本文基于 kubefed v0.5.1 8a2f4a47 进行分析,因为有代码解读所以会又臭又长,如果不想看代码就直接拉到最后
代码解读
以下忽略几个内容
- DNS 相关部分
概念一口闷
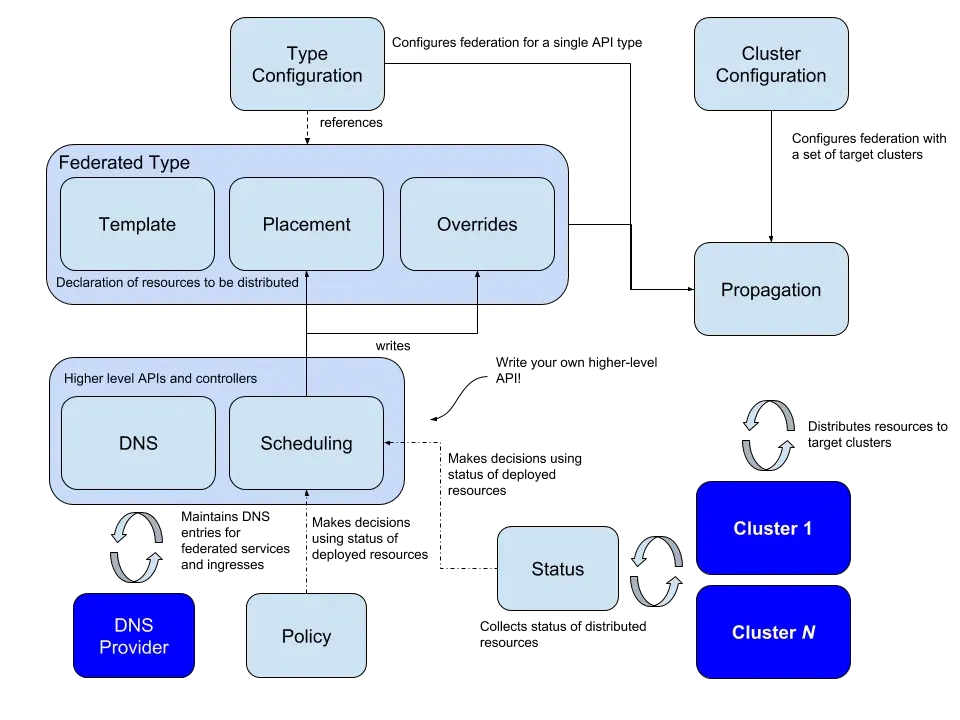
其实这些概念 repo README 也有拉,不过为了阅读方便就搬过来翻译下
Type configuration:对应 FederatedTypeConfig CRD,主要是用来描述什么 API Type 需要被 federated(然后这个 CRD 里主要有一个字段 Propagation 用来标明是否开启传播)
Cluster Configuration:不严格的对应 KubefedCluster CRD,主要是一个集群的集合,但实际上概念中这个还包括了操作对应集群的 KubeConfig 等信息
Federated Type:这货是当我们对某个对象开启 Federate 的时候由 kubefed 生成的一个 CRD,比如给 Deployment 开 Federated,那就会生成一个 FederatedDeployment。在一众的 FederatedType 中不变的就是三件套
- Template(动态生成):实际我们需要创建的 Object 的 Schema,比如 FederatedDeployment 中的 Template 就是个 Deployment。
- Placement(固定):指定需要放置的集群,比如通过名字或者通过标签
- Override(固定):针对于各个集群对 Template 的 patch/override
Scheduling:通过 SchedulingPreference 实现控制各个集群的调度情况,比如当前提供了 Deployment、ReplicaSet 的实例数调度支持,以控制不同集群调度的配比。
当前多集群的结构是:一个 Host Cluster 负责主持大局,然后有无数的 Member Cluster 注册到 Host Cluster 被管理,当然 Host Cluster 可以将自己注册为 Member Cluster。 概括起来就是:一主(Cluster)多从,一挂全挂,横屏 kubefed?
基于上述的概念,咱们可以猜猜是怎么实现的?大概是
- 实现 FederatedCRD(FCRD) 里面包括了我们期望创建的 API Type
- 当我们创建这个 FCRD 时帮我们调度下然后发布到对应的集群上
- 采集点 status
那是事实是?就是这样没错
上代码
咱们看看代码结构吧,不重要的包或者目录我就扔掉了
├── cmd 一切 binary 的入口
│ ├── controller-manager
│ │ └── app
│ │ ├── leaderelection
│ │ └── options
│ ├── hyperfed
│ ├── kubefedctl
│ └── webhook 启动 webhook
│ └── app
├── pkg
│ ├── apis 定义 CRD 的地方
│ │ ├── core
│ │ │ ├── common
│ │ │ ├── typeconfig
│ │ │ ├── v1alpha1
│ │ │ └── v1beta1
│ │ │ ├── defaults
│ │ │ └── validation
│ │ ├── multiclusterdns
│ │ │ └── v1alpha1
│ │ └── scheduling
│ │ └── v1alpha1
│ ├── client 实现的一个基于 runtime.Object receiver 的 Kubernetes client
│ │ └── generic
│ │ └── scheme
│ ├── controller ControllerManager 的主要组成
│ │ ├── dnsendpoint
│ │ ├── federatedtypeconfig
│ │ ├── ingressdns
│ │ ├── kubefedcluster
│ │ ├── schedulingmanager
│ │ ├── schedulingpreference
│ │ ├── servicedns
│ │ ├── status
│ │ ├── sync 核心同步逻辑
│ │ │ ├── dispatch
│ │ │ ├── status
│ │ │ └── version
│ │ ├── testdata
│ │ │ └── fixtures
│ │ ├── util
│ │ │ ├── finalizers
│ │ │ ├── planner
│ │ │ └── podanalyzer
│ │ └── webhook
│ │ ├── federatedtypeconfig
│ │ ├── kubefedcluster
│ │ └── kubefedconfig
│ ├── features 存放 Feature 的基本信息和开关
│ ├── kubefedctl kubefedctl 的实际实现包
│ │ ├── enable
│ │ ├── federate
│ │ ├── options
│ │ ├── orphaning
│ │ └── util
│ ├── metrics 各项暴露的监测指标
│ └── schedulingtypes 给 SchedulingManager 提供各种 API Type 做 SchedulingPreference 计算的小弟以上基本可以看到整个代码组成的结构:
- kubefedctl:提供 cli 来控制各种 CRD 创建修改
- webhook:Kubernetes Admission Webhook,当前用了 mutating 和 validating 的 hook,接管的对象有 federatedTypeConfig、kubefedCluster、kuebfedConfig
- controller manager:kubefed 核心所在
咱们就不扯 kuebfedctl 和 webhook 了,直接上 controller 部分,也就是所谓的 kubefed control-panel。不过在这之前,先来看下 kubefed 的数据结构和一些名词定义(比如缩写省得写一大串)
主要数据结构
metav1.APIResource
这货是定义一个 Type 的基本元信息(就不翻译了)
// APIResource specifies the name of a resource and whether it is namespaced.
type APIResource struct {
// name is the plural name of the resource.
Name string `json:"name" protobuf:"bytes,1,opt,name=name"`
// singularName is the singular name of the resource. This allows clients to handle plural and singular opaquely.
// The singularName is more correct for reporting status on a single item and both singular and plural are allowed
// from the kubectl CLI interface.
SingularName string `json:"singularName" protobuf:"bytes,6,opt,name=singularName"`
// namespaced indicates if a resource is namespaced or not.
Namespaced bool `json:"namespaced" protobuf:"varint,2,opt,name=namespaced"`
// group is the preferred group of the resource. Empty implies the group of the containing resource list.
// For subresources, this may have a different value, for example: Scale".
Group string `json:"group,omitempty" protobuf:"bytes,8,opt,name=group"`
// version is the preferred version of the resource. Empty implies the version of the containing resource list
// For subresources, this may have a different value, for example: v1 (while inside a v1beta1 version of the core resource's group)".
Version string `json:"version,omitempty" protobuf:"bytes,9,opt,name=version"`
// kind is the kind for the resource (e.g. 'Foo' is the kind for a resource 'foo')
Kind string `json:"kind" protobuf:"bytes,3,opt,name=kind"`
// verbs is a list of supported kube verbs (this includes get, list, watch, create,
// update, patch, delete, deletecollection, and proxy)
Verbs Verbs `json:"verbs" protobuf:"bytes,4,opt,name=verbs"`
// shortNames is a list of suggested short names of the resource.
ShortNames []string `json:"shortNames,omitempty" protobuf:"bytes,5,rep,name=shortNames"`
// categories is a list of the grouped resources this resource belongs to (e.g. 'all')
Categories []string `json:"categories,omitempty" protobuf:"bytes,7,rep,name=categories"`
// The hash value of the storage version, the version this resource is
// converted to when written to the data store. Value must be treated
// as opaque by clients. Only equality comparison on the value is valid.
// This is an alpha feature and may change or be removed in the future.
// The field is populated by the apiserver only if the
// StorageVersionHash feature gate is enabled.
// This field will remain optional even if it graduates.
// +optional
StorageVersionHash string `json:"storageVersionHash,omitempty" protobuf:"bytes,10,opt,name=storageVersionHash"`
}然后 kubefed 自己撸了一个 APIResource 两者在关键信息上差别不大
// APIResource defines how to configure the dynamic client for an API resource.
type APIResource struct {
// metav1.GroupVersion is not used since the json annotation of
// the fields enforces them as mandatory.
// Group of the resource.
// +optional
Group string `json:"group,omitempty"`
// Version of the resource.
Version string `json:"version"`
// Camel-cased singular name of the resource (e.g. ConfigMap)
Kind string `json:"kind"`
// Lower-cased plural name of the resource (e.g. configmaps). If
// not provided, it will be computed by lower-casing the kind and
// suffixing an 's'.
PluralName string `json:"pluralName"`
// Scope of the resource.
Scope apiextv1b1.ResourceScope `json:"scope"`
}FederatedTypeConfig
缩写 FTC,用于生成 FederatedType
type FederatedTypeConfig struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec FederatedTypeConfigSpec `json:"spec"`
// +optional
Status FederatedTypeConfigStatus `json:"status,omitempty"`
}
// 主要的定义都在这
// FederatedTypeConfigSpec defines the desired state of FederatedTypeConfig.
type FederatedTypeConfigSpec struct {
// The configuration of the target type. If not set, the pluralName and
// groupName fields will be set from the metadata.name of this resource. The
// kind field must be set.
// 指定我们期望 Federated 的目标类型
TargetType APIResource `json:"targetType"`
// Whether or not propagation to member clusters should be enabled.
// 表明是否需要 sync,当前只有 Enable 和 Disable
Propagation PropagationMode `json:"propagation"`
// Configuration for the federated type that defines (via
// template, placement and overrides fields) how the target type
// should appear in multiple cluster.
// 指定我们生成的 APIResource 是什么样的,说白就是生成的 FederatedCRD 中名字、group、version 等信息
FederatedType APIResource `json:"federatedType"`
// Configuration for the status type that holds information about which type
// holds the status of the federated resource. If not provided, the group
// and version will default to those provided for the federated type api
// resource.
// +optional
// target type 的 Status 类型
StatusType *APIResource `json:"statusType,omitempty"`
// Whether or not Status object should be populated.
// +optional
// 是否进行 Target Type Status 做采集
StatusCollection *StatusCollectionMode `json:"statusCollection,omitempty"`
}KubefedCluster
这个结构体是 member cluster 注册到 Host cluster 时的产物。在 Spec 中主要存储对应集群的 APIServer 和访问凭证, 而在 Status 中主要存储的是集群的健康状态以及如包含的 Region、Zone 等。
type KubeFedCluster struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec KubeFedClusterSpec `json:"spec"`
// +optional
Status KubeFedClusterStatus `json:"status,omitempty"`
}
// KubeFedClusterSpec defines the desired state of KubeFedCluster
type KubeFedClusterSpec struct {
// The API endpoint of the member cluster. This can be a hostname,
// hostname:port, IP or IP:port.
APIEndpoint string `json:"apiEndpoint"`
// CABundle contains the certificate authority information.
// +optional
CABundle []byte `json:"caBundle,omitempty"`
// Name of the secret containing the token required to access the
// member cluster. The secret needs to exist in the same namespace
// as the control plane and should have a "token" key.
SecretRef LocalSecretReference `json:"secretRef"`
// DisabledTLSValidations defines a list of checks to ignore when validating
// the TLS connection to the member cluster. This can be any of *, SubjectName, or ValidityPeriod.
// If * is specified, it is expected to be the only option in list.
// +optional
DisabledTLSValidations []TLSValidation `json:"disabledTLSValidations,omitempty"`
}
// KubeFedClusterStatus contains information about the current status of a
// cluster updated periodically by cluster controller.
type KubeFedClusterStatus struct {
// Conditions is an array of current cluster conditions.
Conditions []ClusterCondition `json:"conditions"`
// Zones are the names of availability zones in which the nodes of the cluster exist, e.g. 'us-east1-a'.
// +optional
Zones []string `json:"zones,omitempty"`
// Region is the name of the region in which all of the nodes in the cluster exist. e.g. 'us-east1'.
// +optional
Region *string `json:"region,omitempty"`
}KubefedConfig
这个是 kubefed 的配置,不太像深入,这个大家各自看代码就好,本身涉及不多
FederatedType 是怎么创建的
最开始,我们会手动或者通过 kubefed client 或者什么其他姿势,反正就是创建了一个 FederatedTypeConfig 就像下面
apiVersion: core.kubefed.io/v1beta1
kind: FederatedTypeConfig
metadata:
annotations:
meta.helm.sh/release-name: kubefed
meta.helm.sh/release-namespace: kube-federation-system
finalizers:
- core.kubefed.io/federated-type-config
generation: 1
labels:
app.kubernetes.io/managed-by: Helm
name: deployments.apps
namespace: kube-federation-system
spec:
federatedType:
group: types.kubefed.io
kind: FederatedDeployment
pluralName: federateddeployments
scope: Namespaced
version: v1beta1
propagation: Enabled
targetType:
group: apps
kind: Deployment
pluralName: deployments
scope: Namespaced
version: v1将 apps/v1.Deployment federated 了,federatedType 表明最后生成的 FCRD 的基本信息,targetType 就是我们想要 federated 的 Type 信息,propagation 这边设为开启。当这样一个 Object 被创建或者更新时,FederatedTypeConfigController 也就对应 repo 中的 pkg/controller/federatedtypeconfig 就会开始工作(如果启动了的话,他由 cmd 里的 controller-manager 拉起,不赘述)。
FederatedTypeConfig 的创建
注意:FTC 的 name 是为 targetType 的 name.group 组成(core group 可省略 group,毕竟其可为「空串」)
启动时在 cmd 中 controller-manager 初始化 FederatedTypeConfigController
// newController returns a new controller to manage FederatedTypeConfig objects.
func newController(config *util.ControllerConfig) (*Controller, error) {
...创建 genericClient...
c := &Controller{
controllerConfig: config,
client: genericclient,
stopChannels: make(map[string]chan struct{}),
}
// 创建了一个延迟队列包裹的 c.reconcile,后续我们通过往 worker 塞东西后入延迟队列再到 c.reconcile 处理
c.worker = util.NewReconcileWorker(c.reconcile, util.WorkerTiming{})
// 根据用户设定的 `KubeFedNamespace` 去起 FTC 的 informer,这边之所以是特定而非全部 namespace
// 主要是因为 kubefed 可以是 namespace level 的 control,如果是直接监听全部的话当是 namespace scope 的时候会有权限问题
// 当 informer 有新东西的时候就会通过 c.worker.EnqueueObject 入到 c.reconcile 去处理。
//
// **其他几个 controller 也是类似的套路,如果没有特别的就不赘述了**
//
// 这边的 store 是 `cache.Store` 也就是原生 cache 存储的地方
// c.controller 实际为 InformerController 可以不用过多关注
c.store, c.controller, err = util.NewGenericInformer(
kubeConfig,
config.KubeFedNamespace,
&corev1b1.FederatedTypeConfig{},
util.NoResyncPeriod,
c.worker.EnqueueObject,
)
if err != nil {
return nil, err
}
return c, nil
}
初始化后通过 Controller.Run(stopCh) 启动这个 Controller。当我们创建或者修改了一个 FederatedTypeConfig 的时候,informer 会发现并通过 EnqueueObject 塞到 FederatedTypeConfigController.concile 做处理,那就看看这货现在怎么处理 FTC 的吧。
func (c *Controller) reconcile(qualifiedName util.QualifiedName) util.ReconciliationStatus {
// 省略一坨从 cache 拿 FTC 的过程,没啥特别的
syncEnabled := typeConfig.GetPropagationEnabled()
statusEnabled := typeConfig.GetStatusEnabled()
limitedScope := c.controllerConfig.TargetNamespace != metav1.NamespaceAll
// 对于开了 sync 并且当前 kubefed 限制在特定 namespace 的,然后 target type 又是非 namesapced。这种情况就是非预期,需要关闭他的 sync。
if limitedScope && syncEnabled && !typeConfig.GetNamespaced() {
// 如果没取到 stop ch 则构造一个
// 问题点:没有 get 到为什么需要造一个,因为从总体语义来说,如果能 get 到说明对应 sync Contoller是 running 的
_, ok := c.getStopChannel(typeConfig.Name)
if !ok {
// 塞个新的到 StopChannel
}
// 更新 FTC 的 status 并 return 终止流程
}
statusKey := typeConfig.Name + "/status"
syncStopChan, syncRunning := c.getStopChannel(typeConfig.Name)
statusStopChan, statusRunning := c.getStopChannel(statusKey)
deleted := typeConfig.DeletionTimestamp != nil
if deleted {
// 如果 sync controller 和 status controller 开着,就关掉它们
// 如果 federatedNamespace 要被删除的话,按总体的设计来说,namespace 内的 Namespaced FederatedTypes 需要全部重新回炉下
if typeConfig.IsNamespace() {
// 这个函数会将 非 Namespace 对象但是 namespaced 的 FederatedTypes 全部重新入 reconcile 处理下
c.reconcileOnNamespaceFTCUpdate()
}
// 移除 finalizer
err := c.removeFinalizer(typeConfig)
return util.StatusAllOK
}
// 确保 finalizer 都设置到位了
updated, err := c.ensureFinalizer(typeConfig)
if err != nil {
return util.StatusError
} else if updated && typeConfig.IsNamespace() {
// 这边是新建的 Namespace FTC 的时候会进入的流程,这时候会把之前 Namespaced 的 FTC 都过一把,
// 因为早前因为没有 Namespace 的存在,所以他们都不会创建 sync controller,这时候需要全部拉起来跑。
// 问题点:但其实这货根据这个作为条件也很奇怪,因为我如果手动去掉 FTC 的 finalizer 也会触发 updated。。。
c.reconcileOnNamespaceFTCUpdate()
}
startNewSyncController := !syncRunning && syncEnabled
// 如果 sync controller 在运行,但是不需要再开启了或者当前是个 namespaced 的 type 而且对应的 namespace FTC 不存在,也需要把 sync controller 停掉
stopSyncController := syncRunning && (!syncEnabled || (typeConfig.GetNamespaced() && !c.namespaceFTCExists()))
if startNewSyncController {
// 通过 c.startSyncController(typeConfig) 启动 sync controller
} else if stopSyncController {
// 通过 c.stopController(typeConfig.Name, syncStopChan) 关停 sync controller
}
startNewStatusController := !statusRunning && statusEnabled
stopStatusController := statusRunning && !statusEnabled
if startNewStatusController {
// c.startStatusController(statusKey, typeConfig) 启动 status controller
} else if stopStatusController {
c.stopController(statusKey, statusStopChan)
}
// sync controller 已经开着了,但是 FTC status 的 ObservedGeneration 跟 FTC 的 Generation 不一致,
// 那么说明可能 out-of-sync,所以重启下 sync controller
if !startNewSyncController && !stopSyncController &&
typeConfig.Status.ObservedGeneration != typeConfig.Generation {
if err := c.refreshSyncController(typeConfig); err != nil {
runtime.HandleError(err)
return util.StatusError
}
}
// 更新 SyncController 和 StatusController 到 FTC
return util.StatusAllOK
}KubeFedSyncController
在上文中,当有一个 FTC 存在且需要 sync 的时候,就会通过 startSyncController(tc *corev1b1.FederatedTypeConfig) 去启动一个 SyncController,接下来看看 SyncController 的启动和工作内容。
func (c *Controller) startSyncController(tc *corev1b1.FederatedTypeConfig) error {
ftc := tc.DeepCopyObject().(*corev1b1.FederatedTypeConfig)
kind := ftc.Spec.FederatedType.Kind
// 如果是一个 namespaced target type,那么我们需要在启动前确保 FederatedNamespace 已经开启了,不然无法进行
var fedNamespaceAPIResource *metav1.APIResource
if ftc.GetNamespaced() {
var err error
fedNamespaceAPIResource, err = c.getFederatedNamespaceAPIResource()
if err != nil {
return errors.Wrapf(err, "Unable to start sync controller for %q due to missing FederatedTypeConfig for namespaces", kind)
}
}
stopChan := make(chan struct{})
// 实际启动一个 SyncController
err := synccontroller.StartKubeFedSyncController(c.controllerConfig, stopChan, ftc, fedNamespaceAPIResource)
if err != nil {
close(stopChan)
return errors.Wrapf(err, "Error starting sync controller for %q", kind)
}
klog.Infof("Started sync controller for %q", kind)
// 塞到 stopChannels 标明这个 FTC 已经有了 running 的 SyncController
c.lock.Lock()
defer c.lock.Unlock()
c.stopChannels[ftc.Name] = stopChan
return nil
}
// pkg/controller/sync/controller.go
以下
func StartKubeFedSyncController(controllerConfig *util.ControllerConfig, stopChan <-chan struct{}, typeConfig typeconfig.Interface, fedNamespaceAPIResource *metav1.APIResource) error {
controller, err := newKubeFedSyncController(controllerConfig, typeConfig, fedNamespaceAPIResource)
if err != nil {
return err
}
// 问题点:这是一个非常诡异的东西,从注释看仅仅为了测试。。。
if controllerConfig.MinimizeLatency {
controller.minimizeLatency()
}
klog.Infof(fmt.Sprintf("Starting sync controller for %q", typeConfig.GetFederatedType().Kind))
controller.Run(stopChan)
return nil
}
// newKubeFedSyncController returns a new sync controller for the configuration
func newKubeFedSyncController(controllerConfig *util.ControllerConfig, typeConfig typeconfig.Interface, fedNamespaceAPIResource *metav1.APIResource) (*KubeFedSyncController, error) {
// 初始化 generic client 和一个 event recorder
...
s := &KubeFedSyncController{
clusterAvailableDelay: controllerConfig.ClusterAvailableDelay,
clusterUnavailableDelay: controllerConfig.ClusterUnavailableDelay,
smallDelay: time.Second * 3,
eventRecorder: recorder,
typeConfig: typeConfig,
hostClusterClient: client,
skipAdoptingResources: controllerConfig.SkipAdoptingResources,
limitedScope: controllerConfig.LimitedScope(),
}
s.worker = util.NewReconcileWorker(s.reconcile, util.WorkerTiming{
ClusterSyncDelay: s.clusterAvailableDelay,
})
// Build deliverer for triggering cluster reconciliations.
s.clusterDeliverer = util.NewDelayingDeliverer()
targetAPIResource := typeConfig.GetTargetType()
// 起一个 informer watch 在 HostCluster 的 TargetType 上,适时的如 worker 队列。
// 重点:并处理集群的健康状态变更,当 member cluster 有状态变更的时候,直接重新过一遍全部的 Target Type Object
var err error
s.informer, err = util.NewFederatedInformer(
controllerConfig,
client,
&targetAPIResource,
func(obj pkgruntime.Object) {
qualifiedName := util.NewQualifiedName(obj)
s.worker.EnqueueForRetry(qualifiedName)
},
&util.ClusterLifecycleHandlerFuncs{
ClusterAvailable: func(cluster *fedv1b1.KubeFedCluster) {
// When new cluster becomes available process all the target resources again.
s.clusterDeliverer.DeliverAt(allClustersKey, nil, time.Now().Add(s.clusterAvailableDelay))
},
// When a cluster becomes unavailable process all the target resources again.
ClusterUnavailable: func(cluster *fedv1b1.KubeFedCluster, _ []interface{}) {
s.clusterDeliverer.DeliverAt(allClustersKey, nil, time.Now().Add(s.clusterUnavailableDelay))
},
},
)
if err != nil {
return nil, err
}
// 重点
s.fedAccessor, err = NewFederatedResourceAccessor(
controllerConfig, typeConfig, fedNamespaceAPIResource,
client, s.worker.EnqueueObject, recorder)
if err != nil {
return nil, err
}
return s, nil
}在 FTCController 部分的 SyncController 启动逻辑不会太难理解,总体可以理解为:如果是 Namespaced Type 那么需要保证 FederatedNamespace 存在,不然就不进行创建。如果只是普通的 Type 则直接开启,最后在 channel 注册下。
FederatedResourceAccessor
// pkg/controller/sync/accessor.go
type FederatedResourceAccessor interface {
Run(stopChan <-chan struct{})
HasSynced() bool
FederatedResource(qualifiedName util.QualifiedName) (federatedResource FederatedResource, possibleOrphan bool, err error)
VisitFederatedResources(visitFunc func(obj interface{}))
}
func NewFederatedResourceAccessor(
controllerConfig *util.ControllerConfig,
typeConfig typeconfig.Interface,
fedNamespaceAPIResource *metav1.APIResource,
client genericclient.Client,
enqueueObj func(pkgruntime.Object),
eventRecorder record.EventRecorder) (FederatedResourceAccessor, error) {
// 这个函数的基本流程会是
// 获取 FederatedType 的 client 和 informer
// 如果 TargetType 是个 Namespace 就再初始化下 对应 namespace 的 client 和 informer
// 接着,如果 TargetType 是个 Namespaced Type 那么会再初始化一下 KubeFedNamespace 的 client 和 informer 在 FederatedNamespace 对象变动的时候需要整个 namespace 内的 FederatedResource 全部重新进队列处理
// 再起一个 Version Manager
}Version Manager 这边暂时不细展开代码,主要的工作是
- 当创建 FederatedObject 的时候,会去创建一个
PropagatedVersion其中记录了对应 resource(target resource) 和 template、override 的 version - 基于此 version 我们可以判定一个完整的 FederatedObject 是否需要更新
回到 Accessor,在初始化完后会将 versionManager 及相关的 informer 启动起来。以下是几个 Accessor 的方法
以下判断一个 FederatedType 是否已同步
func (a *resourceAccessor) HasSynced() bool {
kind := a.typeConfig.GetFederatedType().Kind
if !a.versionManager.HasSynced() {
return false
}
if !a.federatedController.HasSynced() {
return false
}
if a.namespaceController != nil && !a.namespaceController.HasSynced() {
return false
}
if a.fedNamespaceController != nil && !a.fedNamespaceController.HasSynced() {
return false
}
return true
}
// 从 eventSource 中获取对应的 FederatedSource 也就是 FederatedType 的实际对象
func (a *resourceAccessor) FederatedResource(eventSource util.QualifiedName) (FederatedResource, bool, error) {
// 问题点:忽略了系统的 namespace,暂时没 get 到为啥
if a.targetIsNamespace && a.isSystemNamespace(eventSource.Name) {
klog.V(7).Infof("Ignoring system namespace %q", eventSource.Name)
return nil, false, nil
}
// Most federated resources have the same name as their targets.
// NamespaceForResource 当前实际是直接 return eventSource.Namespace 所以两个 name 是一样的
targetName := util.QualifiedName{
Namespace: eventSource.Namespace,
Name: eventSource.Name,
}
federatedName := util.QualifiedName{
Namespace: util.NamespaceForResource(eventSource.Namespace, a.fedNamespace),
Name: eventSource.Name,
}
// 这边对 namespace 类型的 FederatedType 做了一个特殊处理。
// A federated type for namespace "foo" is namespaced
// (e.g. "foo/foo"). An event sourced from a namespace in the host
// or member clusters will have the name "foo", and an event
// sourced from a federated resource will have the name "foo/foo".
// In order to ensure object retrieval from the informers, it is
// necessary to derive the target name and federated name from the
// event source.
if a.targetIsNamespace {
// eventSource 是否来自 core.Namespace(就是没有 federated 的那个 object),因为那么 namespace 是非 namespaced,所以这边通过判断 namespace 为空确认
eventSourceIsTarget := eventSource.Namespace == ""
if eventSourceIsTarget {
// Ensure the federated name is namespace qualified.
// 因为当前 eventSource 是 core.Namespace 所以其 federated 的对象所在 namespace 就是其下属
federatedName.Namespace = federatedName.Name
} else {
// Ensure the target name is not namespace qualified.
// 当前 eventSource 是非 core.Namespace 也就是 FederatedNamespace。他的 target 是 core.Namespace 非 namespaced 所以需要置空
targetName.Namespace = ""
}
// 这边为啥不直接就覆盖掉的了?为了凑代码吗?
}
key := federatedName.String()
resource, err := util.ObjFromCache(a.federatedStore, kind, key)
if err != nil {
return nil, false, err
}
// 如果从 federatedType Cache 里取不到并且不是 FederatedNamespace 那么则有可能是 orphan
// 疑问:为啥是 FNS 就不会是 orphan???
if resource == nil {
sourceIsFederatedNamespace := a.targetIsNamespace && eventSource.Namespace != ""
possibleOrphan := !sourceIsFederatedNamespace
return nil, possibleOrphan, nil
}
var namespace *unstructured.Unstructured
if a.targetIsNamespace {
// 这边会确认下 host cluster 中对应需要 propagate 的 namespace 存在
}
var fedNamespace *unstructured.Unstructured
if a.typeConfig.GetNamespaced() {
// 对于 namespaced 的需要确认下 federated namespace 是否开启,不开也没法进行
fedNamespaceName := util.QualifiedName{Namespace: federatedName.Namespace, Name: federatedName.Namespace}
fedNamespace, err = util.ObjFromCache(a.fedNamespaceStore, a.fedNamespaceAPIResource.Kind, fedNamespaceName.String())
if err != nil {
return nil, false, err
}
// If fedNamespace is nil, the resources in member clusters
// will be removed.
}
return &federatedResource{...}, false, nil
}KubeFedSyncController.reconcile
终于回来了,继续理 sync controller 的 reconcile
func (s *KubeFedSyncController) reconcile(qualifiedName util.QualifiedName) util.ReconciliationStatus {
if !s.isSynced() {
return util.StatusNotSynced
}
kind := s.typeConfig.GetFederatedType().Kind
fedResource, possibleOrphan, err := s.fedAccessor.FederatedResource(qualifiedName)
if err != nil {
runtime.HandleError(errors.Wrapf(err, "Error creating FederatedResource helper for %s %q", kind, qualifiedName))
return util.StatusError
}
// 可能是 orphan ,在所有集群理把 kubefed.io/managed=true 的标签删除
if possibleOrphan {
apiResource := s.typeConfig.GetTargetType()
gvk := apiResourceToGVK(&apiResource)
klog.V(2).Infof("Ensuring the removal of the label %q from %s %q in member clusters.", util.ManagedByKubeFedLabelKey, gvk.Kind, qualifiedName)
err = s.removeManagedLabel(gvk, qualifiedName)
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to remove the label %q from %s %q in member clusters", util.ManagedByKubeFedLabelKey, gvk.Kind, qualifiedName)
runtime.HandleError(wrappedErr)
return util.StatusError
}
return util.StatusAllOK
}
if fedResource == nil {
return util.StatusAllOK
}
key := fedResource.FederatedName().String()
klog.V(4).Infof("Starting to reconcile %s %q", kind, key)
startTime := time.Now()
defer func() {
klog.V(4).Infof("Finished reconciling %s %q (duration: %v)", kind, key, time.Since(startTime))
metrics.ReconcileFederatedResourcesDurationFromStart(startTime)
}()
if fedResource.Object().GetDeletionTimestamp() != nil {
return s.ensureDeletion(fedResource)
}
// 确保下对应的 FederatedObject 有 finalizer
err = s.ensureFinalizer(fedResource)
if err != nil {
fedResource.RecordError("EnsureFinalizerError", errors.Wrap(err, "Failed to ensure finalizer"))
return util.StatusError
}
// 推到各个集群
return s.syncToClusters(fedResource)
}删除部分需要特别说明下,因为这边涉及到了 kubefed.io/orphan 标签
func (s *KubeFedSyncController) ensureDeletion(fedResource FederatedResource) util.ReconciliationStatus {
fedResource.DeleteVersions()
key := fedResource.FederatedName().String()
kind := fedResource.FederatedKind()
klog.V(2).Infof("Ensuring deletion of %s %q", kind, key)
obj := fedResource.Object()
// 没有 finalizer 就不管了,丢那了
finalizers := sets.NewString(obj.GetFinalizers()...)
if !finalizers.Has(FinalizerSyncController) {
klog.V(2).Infof("%s %q does not have the %q finalizer. Nothing to do.", kind, key, FinalizerSyncController)
return util.StatusAllOK
}
// 如果设定了 kubefed.io/orphan=true 的 annotation 就不会做实际的删除,但是会去掉 finalizer 和 managed 的标签
if util.IsOrphaningEnabled(obj) {
klog.V(2).Infof("Found %q annotation on %s %q. Removing the finalizer.",
util.OrphanManagedResourcesAnnotation, kind, key)
err := s.removeFinalizer(fedResource)
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to remove finalizer %q from %s %q", FinalizerSyncController, kind, key)
runtime.HandleError(wrappedErr)
return util.StatusError
}
klog.V(2).Infof("Initiating the removal of the label %q from resources previously managed by %s %q.", util.ManagedByKubeFedLabelKey, kind, key)
err = s.removeManagedLabel(fedResource.TargetGVK(), fedResource.TargetName())
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to remove the label %q from all resources previously managed by %s %q", util.ManagedByKubeFedLabelKey, kind, key)
runtime.HandleError(wrappedErr)
return util.StatusError
}
return util.StatusAllOK
}
// 真的需要删除的。
// 这边之所以会有 recheck 是因为有些资源如果已经在 deletion 了(DeletionTimestamp != nil) 那就不会再删除。
// deleteFromClusters 里面还有个特殊处理是,如果是删 namespaced 不会需要 recheck,也就是只有删 federatedNamespace 需要
klog.V(2).Infof("Deleting resources managed by %s %q from member clusters.", kind, key)
recheckRequired, err := s.deleteFromClusters(fedResource)
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to delete %s %q", kind, key)
runtime.HandleError(wrappedErr)
return util.StatusError
}
if recheckRequired {
return util.StatusNeedsRecheck
}
return util.StatusAllOK
}
总算要推到各个集群了,这部分我觉得是写的最干脆的。
// syncToClusters ensures that the state of the given object is
// synchronized to member clusters.
func (s *KubeFedSyncController) syncToClusters(fedResource FederatedResource) util.ReconciliationStatus {
clusters, err := s.informer.GetClusters()
if err != nil {
fedResource.RecordError(string(status.ClusterRetrievalFailed), errors.Wrap(err, "Failed to retrieve list of clusters"))
return s.setFederatedStatus(fedResource, status.ClusterRetrievalFailed, nil)
}
selectedClusterNames, err := fedResource.ComputePlacement(clusters)
if err != nil {
fedResource.RecordError(string(status.ComputePlacementFailed), errors.Wrap(err, "Failed to compute placement"))
return s.setFederatedStatus(fedResource, status.ComputePlacementFailed, nil)
}
// 上述两个步骤取了所有集群和相关 FederatedObject 中 placement 涉及的集群
kind := fedResource.TargetKind()
key := fedResource.TargetName().String()
klog.V(4).Infof("Ensuring %s %q in clusters: %s", kind, key, strings.Join(selectedClusterNames.List(), ","))
dispatcher := dispatch.NewManagedDispatcher(s.informer.GetClientForCluster, fedResource, s.skipAdoptingResources)
// Range 所有集群,因为我们需要做回收,所以不能单单 range selectedCluster
for _, cluster := range clusters {
clusterName := cluster.Name
selectedCluster := selectedClusterNames.Has(clusterName)
// 糟糕,选到的集群 NotReady 了,记个错误
if !util.IsClusterReady(&cluster.Status) {
if selectedCluster {
// Cluster state only needs to be reported in resource
// status for clusters selected for placement.
err := errors.New("Cluster not ready")
dispatcher.RecordClusterError(status.ClusterNotReady, clusterName, err)
}
continue
}
rawClusterObj, _, err := s.informer.GetTargetStore().GetByKey(clusterName, key)
if err != nil {
wrappedErr := errors.Wrap(err, "Failed to retrieve cached cluster object")
dispatcher.RecordClusterError(status.CachedRetrievalFailed, clusterName, wrappedErr)
continue
}
var clusterObj *unstructured.Unstructured
if rawClusterObj != nil {
clusterObj = rawClusterObj.(*unstructured.Unstructured)
}
// 如果没选上的集群里有,Target Object 那就干掉
// 潜在风险:多集群加入 kubefed 的时候如果正好命中,那就 GG 了
// Resource should not exist in the named cluster
if !selectedCluster {
if clusterObj == nil {
// Resource does not exist in the cluster
continue
}
if clusterObj.GetDeletionTimestamp() != nil {
// Resource is marked for deletion
dispatcher.RecordStatus(clusterName, status.WaitingForRemoval)
continue
}
if fedResource.IsNamespaceInHostCluster(clusterObj) {
// Host cluster namespace needs to have the managed
// label removed so it won't be cached anymore.
dispatcher.RemoveManagedLabel(clusterName, clusterObj)
} else {
dispatcher.Delete(clusterName)
}
continue
}
// Resource should appear in the named cluster
// 创建或者更新对象
// TODO(marun) Consider waiting until the result of resource
// creation has reached the target store before attempting
// subsequent operations. Otherwise the object won't be found
// but an add operation will fail with AlreadyExists.
if clusterObj == nil {
dispatcher.Create(clusterName)
} else {
dispatcher.Update(clusterName, clusterObj)
}
}
// 等 dispatcher 刚刚的工作都完成了,然后更新下 version map
_, timeoutErr := dispatcher.Wait()
if timeoutErr != nil {
fedResource.RecordError("OperationTimeoutError", timeoutErr)
}
// Write updated versions to the API.
updatedVersionMap := dispatcher.VersionMap()
err = fedResource.UpdateVersions(selectedClusterNames.List(), updatedVersionMap)
if err != nil {
// Versioning of federated resources is an optimization to
// avoid unnecessary updates, and failure to record version
// information does not indicate a failure of propagation.
runtime.HandleError(err)
}
// 更新下传播状态 -> PropagationStatus
collectedStatus := dispatcher.CollectedStatus()
return s.setFederatedStatus(fedResource, status.AggregateSuccess, &collectedStatus)
}从上述这段代码来说,这边没有处理集群挂掉时候的 failover(比如对于 Deployment、ReplicaSet 这类 ReplicaedObject),这部分会留到 SchedulingPreference 那边处理。
Dispatcher
// ManagedDispatcher dispatches operations to member clusters for resources
// managed by a federated resource.
type ManagedDispatcher interface {
UnmanagedDispatcher
Create(clusterName string)
Update(clusterName string, clusterObj *unstructured.Unstructured)
VersionMap() map[string]string
CollectedStatus() status.CollectedPropagationStatus
RecordClusterError(propStatus status.PropagationStatus, clusterName string, err error)
RecordStatus(clusterName string, propStatus status.PropagationStatus)
}
// UnmanagedDispatcher dispatches operations to member clusters for
// resources that are no longer managed by a federated resource.
type UnmanagedDispatcher interface {
OperationDispatcher
Delete(clusterName string)
RemoveManagedLabel(clusterName string, clusterObj *unstructured.Unstructured)
}
// OperationDispatcher provides an interface to wait for operations
// dispatched to member clusters.
type OperationDispatcher interface {
// Wait returns true for ok if all operations completed
// successfully and false if only some operations completed
// successfully. An error is returned on timeout.
Wait() (ok bool, timeoutErr error)
}来看看 Dispatcher 都定义了什么 func
- 增、删、改
- 采集状态、版本
- 等待 dispatch 完成
- 移除 ManagedLabel
咱们主要关注点在增删和 wait ,其他就不看了
Dispatcher.Create
func (d *managedDispatcherImpl) Create(clusterName string) {
// Default the status to an operation-specific timeout. Otherwise
// when a timeout occurs it won't be possible to determine which
// operation timed out. The timeout status will be cleared by
// Wait() if a timeout does not occur.
// 开篇先来个骚动作。
// 以后咱们对于超时的这种处理状态反馈,可以先默认超时,后面成了再改回去。万一漏改了没事,下次再改
d.RecordStatus(clusterName, status.CreationTimedOut)
start := time.Now()
d.dispatcher.incrementOperationsInitiated()
const op = "create"
go d.dispatcher.clusterOperation(clusterName, op, func(client generic.Client) util.ReconciliationStatus {
d.recordEvent(clusterName, op, "Creating")
obj, err := d.fedResource.ObjectForCluster(clusterName)
if err != nil {
return d.recordOperationError(status.ComputeResourceFailed, clusterName, op, err)
}
err = d.fedResource.ApplyOverrides(obj, clusterName)
if err != nil {
return d.recordOperationError(status.ApplyOverridesFailed, clusterName, op, err)
}
// 以上两个步骤:根据 FederatedObject 获取 Spec 然后 apply 下对应集群的 overrides。然后创建一波我们要的 Object
err = client.Create(context.Background(), obj)
if err == nil {
version := util.ObjectVersion(obj)
d.recordVersion(clusterName, version)
metrics.DispatchOperationDurationFromStart("create", start)
return util.StatusAllOK
}
// TODO(marun) Figure out why attempting to create a namespace that
// already exists indicates ServerTimeout instead of AlreadyExists.
// 因为 controller-runtime 的 client 实现关系,所以这边的 namespace 重复创建会反馈为 timeout
alreadyExists := apierrors.IsAlreadyExists(err) || d.fedResource.TargetKind() == util.NamespaceKind && apierrors.IsServerTimeout(err)
if !alreadyExists {
return d.recordOperationError(status.CreationFailed, clusterName, op, err)
}
// Attempt to update the existing resource to ensure that it
// is labeled as a managed resource.
err = client.Get(context.Background(), obj, obj.GetNamespace(), obj.GetName())
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to retrieve object potentially requiring adoption")
return d.recordOperationError(status.RetrievalFailed, clusterName, op, wrappedErr)
}
// 完全不知道 adoptingResource 啥意思啊。。。盲猜:已存在的资源。
// 跟其他同学聊了下,这货比较准确应该翻译为:从别处接管来的资源。
if d.skipAdoptingResources && !d.fedResource.IsNamespaceInHostCluster(obj) {
_ = d.recordOperationError(status.AlreadyExists, clusterName, op, errors.Errorf("Resource pre-exist in cluster"))
return util.StatusAllOK
}
d.recordError(clusterName, op, errors.Errorf("An update will be attempted instead of a creation due to an existing resource"))
d.Update(clusterName, obj)
metrics.DispatchOperationDurationFromStart("update", start)
return util.StatusAllOK
})
}Dispatcher.Update
func (d *managedDispatcherImpl) Update(clusterName string, clusterObj *unstructured.Unstructured) {
d.RecordStatus(clusterName, status.UpdateTimedOut)
d.dispatcher.incrementOperationsInitiated()
const op = "update"
go d.dispatcher.clusterOperation(clusterName, op, func(client generic.Client) util.ReconciliationStatus {
if util.IsExplicitlyUnmanaged(clusterObj) {
err := errors.Errorf("Unable to manage the object which has label %s: %s", util.ManagedByKubeFedLabelKey, util.UnmanagedByKubeFedLabelValue)
return d.recordOperationError(status.ManagedLabelFalse, clusterName, op, err)
}
obj, err := d.fedResource.ObjectForCluster(clusterName)
if err != nil {
return d.recordOperationError(status.ComputeResourceFailed, clusterName, op, err)
}
// 保留了原有的 Version、finalizer、annotation 和实例数,以及部分保留 service 和 service account
err = RetainClusterFields(d.fedResource.TargetKind(), obj, clusterObj, d.fedResource.Object())
if err != nil {
wrappedErr := errors.Wrapf(err, "failed to retain fields")
return d.recordOperationError(status.FieldRetentionFailed, clusterName, op, wrappedErr)
}
err = d.fedResource.ApplyOverrides(obj, clusterName)
if err != nil {
return d.recordOperationError(status.ApplyOverridesFailed, clusterName, op, err)
}
// 比对版本确认是否需要更新,避免盲目更新
version, err := d.fedResource.VersionForCluster(clusterName)
if err != nil {
return d.recordOperationError(status.VersionRetrievalFailed, clusterName, op, err)
}
if !util.ObjectNeedsUpdate(obj, clusterObj, version) {
// Resource is current
return util.StatusAllOK
}
// Only record an event if the resource is not current
d.recordEvent(clusterName, op, "Updating")
err = client.Update(context.Background(), obj)
if err != nil {
return d.recordOperationError(status.UpdateFailed, clusterName, op, err)
}
d.setResourcesUpdated()
version = util.ObjectVersion(obj)
d.recordVersion(clusterName, version)
return util.StatusAllOK
})
}
Dispatcher.Wait
func (d *managedDispatcherImpl) Wait() (bool, error) {
...
Wait 主要是干两件事情,等待 update、delete 等等操作结束,然后更新下 status
}这部分没啥坑,不赘述
小结
以上基本是可以 cover 整个 kubefed 的在多集群传播工作(propagation)原理了,然后还剩下调度部分、潜在坑、场景和一些感受留到下篇写。
整体来说除了一些蜜汁代码倒还好,有些 namespace、cluster level 的下层 object reconcile 比较蛋疼不过也确实没有特别好的办法